PE Files #
winnt.h header file.
A Portable Executable (PE) file is the standard format created by Microsoft for binary files like EXEs and DLLs. The structure of a PE file below1:
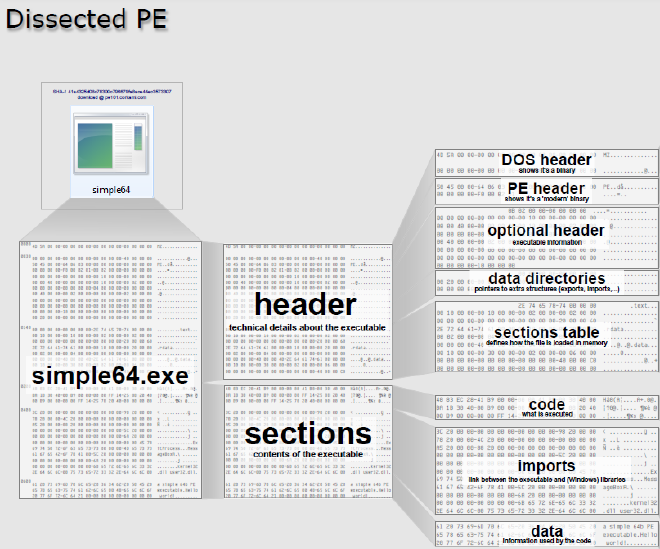
When a PE file is run, it will be copied into memory along with any dependences it requires such as imported binaries for the functions they export. Because of advances in security, the memory region they are copied into is randomized every time. This process is called Address Space Layout Randomization (ASLR). In other words the address for functions, headers, or any other part of a PE file will not be the same for each instance. Instead, this is solved with Relative Virtual Addresses (RVAs). RVAs are offsets in memory relative to the base address of the PE file. To calculate the address in which something sits, take the base address of the PE file and add the RVA associated with the desired location.
Headers #
Headers are the first parts of the PE file. These contain information about the file and what is needed in order to be executed or used. I won’t go into detail for all headers and sections for the sake of brevity but the important items to note are that the DOS header includes: the magic bytes, values about the contents of the file and subsequent sections, and the RVA of the address within the file on disk for the PE header (NT header). The DOS header will always signify the start of a PE file.
e_lfanew member within the struct is the aforementioned RVA to the PE header.
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header
WORD e_magic; // Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;Immediately after the DOS header will be the DOS stub which is there essentially for compatibility reasons. If an executable file were to be loaded in a DOS system, the OS would be able to run the stub because it’s a 16 bit program. If you have ever run Strings on any Windows binary, you’ve likely encountered the famous text: “This program cannot be run in DOS mode.”
The PE header holds more information about the contents of the file and subsequent sections. More importantly it contains the structure for the Optional header! The Optional header contains A LOT of information needed later when creating the malware. It may be called the Optional header, but it is required. Some important ones include pointers to the beginning of some sections, the preferred base address, and an array of Data Directory structs.
typedef struct _IMAGE_NT_HEADERS64 {
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER64 OptionalHeader;
} IMAGE_NT_HEADERS64, *PIMAGE_NT_HEADERS64;typedef struct _IMAGE_OPTIONAL_HEADER64 {
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
ULONGLONG ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
ULONGLONG SizeOfStackReserve;
ULONGLONG SizeOfStackCommit;
ULONGLONG SizeOfHeapReserve;
ULONGLONG SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER64, *PIMAGE_OPTIONAL_HEADER64;Directories #
A Data Directory structure is essentially used to hold information about important directories (and by extension, tables). Specifically the structure contains the virtual address in which the Directory Entry is located as well as the size of the entry. The array of Data Directory structs is specifically ordered so that each index contains a specific entry. For example the first index is the Data Directory structure for the Export Directory, whereas the index after that is the structure for the Import Directory. These are very important to note as they contain both the Export Address Table (EAT) and the Import Address Table (IAT) respectively.
Just as it sounds, the Export Directory is the place where all exported functions can be found within the PE file. Take ntdll.dll for example: Let’s say we wanted to call the NtCreateFile function. To find where that function is located in memory and call it that way, we would have to search the Export Directory of ntdll.dll to get the address of the function. However, that may not be as simple as it sounds. Here is why.
The last 3 members of the struct are a set of arrays that play a critical role in how the locations of functions are resolved. There are two ways that resolution can happen: by searching first for the name of the function, and second, by the biased ordinal number.
Export Directory #
AddressOfFunctions, AddressOfNames, and AddressOfNameOrdinals members which are the arrays I mentioned above.
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name;
DWORD Base;
DWORD NumberOfFunctions;
DWORD NumberOfNames;
DWORD AddressOfFunctions; // RVA from base of image
DWORD AddressOfNames; // RVA from base of image
DWORD AddressOfNameOrdinals; // RVA from base of image
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;To start, let’s take a step back and see what the arrays are for and the relationship between them. Shown below is a good visualization of how these arrays work together2:
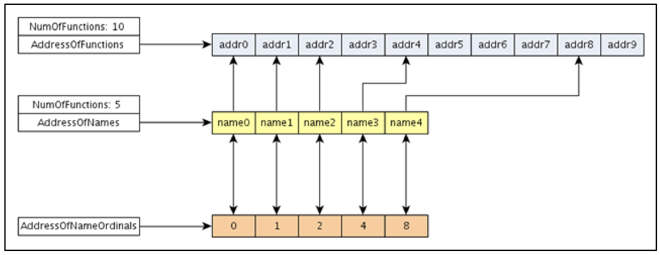
Simply stated the AddressOfNames is the array that contains the names of the exported functions of the binary. The index of the function name in that array is directly correlated to the index of the AddressOfNameOrdinals array. That will give you the ordinal number (index) for where to find said function’s address via an RVA in the AddressOfFunctions array.
Returning to the diagram above, let’s say we wanted to use ’name2’ from the imaginary binary’s exported functions. The first step would be to go into the array AddressOfNames starting with the first index and compare the names of the functions until we find a match. In this case, it is our third index. The next step would be to go into the AddressOfNameOrdinals array at the third index to find the ordinal. In this example it would be 2. (It isn’t always this simple; sometimes it could be ordinal 102.) That ordinal is the index for where to search in the AddressOfFunctions to get the RVA. In this case, we would get the RVA addr2 because the ordinal was 2.
However to save memory, and especially if the binary has hundreds or thousands of exported functions, it may be wise to use ordinal numbers instead of function names. These are called “biased ordinals.” The distinction depends on how the ordinal is calculated. Unbiased ordinals are used internally to calculate the index of where the RVA is located within the AddressOfFunctions. Biased ordinals are calculated by adding the Base member from the Export Directory to the ordinal number. The result is used externally to call exported functions.
Base member is the starting number in which the biased ordinals start (typically the Base member is set to 1)
Going back to the example, let’s say we knew the biased ordinal of the function we wanted to call. Assume the Base is 1 and the biased ordinal is 3. What we would do is subtract the Base from the ordinal (3-1) which equals 2. That means the index that we need to go to in the AddressOfFunctions array is 2. Looking at the diagram, this would be an RVA of addr2.
Import Directory #
Moving onto the Import Directory. When the PE files need to use exported functions from other binaries, this is how the loader will determine which functions from which binaries are needed and where to find them in memory. Unlike with the Export Directory, the Import Directory doesn’t have a dedicated “import directory” struct. Instead it starts with an array of Import Descriptor structs and ends with a NULLed out struct.
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date\time stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;Before diving into the specific attributes of the structures, it’s important to know how the import resolution works and how it functions. Essentially there are three main parts: the Import Directory Table (IDT), the Import Lookup Table (ILT), and the Import Address Table (IAT). When the PE file gets copied to memory in order to be executed, the loader will eventually need to figure out what binaries are required to be coped into memory as well as the functions’ addresses needed for the PE file to function correctly. The loader will then begin with the IDT to figure out what imported binaries are needed. However, there is no need to catalog every function of the imported binaries and by extension, its addresses. To save time, memory, and CPU cycles, the loader will attempt to resolve only the needed functions. This is where the ILT comes into play. The ILT contains an array of RVAs that point to the Hint/Name table. The Hint/Name table contains Hint/Name pairs in which for every function imported from the given binary, there will be a Hint/Name entry for it.
Take for example a PE file that imports the NtCreateFile function from ntdll.dll. There will be an IDT entry for ntdll.dll and within that, there will be an ILT entry for NtCreateFile which will have a Hint/Name pair for that function.
The Hint/Name pair is fairly straight forward. As mentioned, there is optimization built into how PE files work. Instead of recursively going through every single exported function of the imported binary (process explained above in the Export Directory section), the ILT gives a “hint” of the most likely location of the required function. The loader will then use the hint as a “best guess” and associate the hint as an index to the AddressOfNames array. The given function name in the Hint/Name pair is then compared to the string within that index. If there is a match, it proceeds with resolving the exported functions address. If no match it attempts to resolve the functions address by name instead. Once it has resolved the address in which the function lies, it will add that as an entry within the IAT.
The IAT is the last (and arguably the most important) table. It starts out initialized so that each entry points to its corresponding Hint/Name table entry. Then, for each function that it resolves, it overrides the IAT entry with that functions RVA. In other words, the IAT and ILT will be exactly the same on disk and right before import resolution happens in memory. After this process concludes, the IAT will then contain the RVAs of the functions. This is helpful when the PE file needs to call that function, it will directly parse the IAT for where to find the function in memory.
Moving on to the layout of the structs, let’s look at how they are laid out. Starting with the union in the IDT, both of the members are effectively doing the same thing. The Characteristic is mostly deprecated and the OriginalFirstThunk member is an RVA to the ILT. The Name member will contain the name of the imported binary, and the FirstThunk member is the RVA to the start of the IAT.
OriginalFirstThunk and FirstThunk members are of the THUNK_DATA type. The structure for these is given below:
typedef struct _IMAGE_THUNK_DATA64 {
union {
ULONGLONG ForwarderString; // PBYTE
ULONGLONG Function; // PDWORD
ULONGLONG Ordinal;
ULONGLONG AddressOfData; // PIMAGE_IMPORT_BY_NAME
} u1;
} IMAGE_THUNK_DATA64;
typedef IMAGE_THUNK_DATA64 * PIMAGE_THUNK_DATA64;These structs contain the the data required for either the ILT or the IAT. The former will contain a pointer to the Hint/Name entry; the latter indicates the RVA to the IAT entry.
IMPORT_BY_NAME struct shown below:
typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint;
CHAR Name[1];
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;As you can see, the structure has two members, one for the hint and the other for the name of the function.
Sections #
There are typically 7 sections following the headers and data directories:
| Section | Contains |
|---|---|
| .text | Executable code |
| .rdata | Read-only data |
| .data | Initialized data |
| .pdata | Exception handling data |
| .idata | Import data (the import directory is actually held here) |
| .rsrc | Resources (icons, pictures, etc.) |
| .reloc | Relocations (how statically programmed addresses map to ASLR) |
The compiler can add more sections if needed but these are the common ones-found inside most PE files. To get the gears turning, each section can be somewhat manipulated to intentionally obfuscate some malicious capabilities by the location of certain information.
For example, if we had a uint8 variable called varOne, that variable would be stored in the .text section. However, if we made that a constant variable, it would instead be stored in the .rdata section. Likewise, if there is a byte array that is needed, why not convert it to a .jpg file and that would be stored into the .rsrc section? These are examples of a few ways to facilitate the acquisition and intentional manipulation of data within the PE file sections.
VirtualAddress, NumberOfRelocations, and PointerToRelocations. The SECTION_HEADER struct as shown below:
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;An additional section that may be useful to understand is .reloc. For a few reasons, it is helpful to know how relocations work and how to calculate them. One is that reflective DLLs will need to do relocations manually in order to work.
Any statically programmed addresses will need to be changed due to ASLR. This is done with relocations. Relocations are calculated by taking the delta between the ImageBase address (the preferred base address) inside the Optional header and the actual base address of the PE file (allocated by ASLR). After determining the delta, add it to the addresses within the relocation table.
BASE_RELOCATION structs. These have two members: VirtualAddress and SizeOfBlock. The former is the RVA of the address to which the relocation needs to be applied. The latter is the size or amount of bytes needed to be relocated. Here is the aforementioned relocation struct:
typedef struct _IMAGE_BASE_RELOCATION {
DWORD VirtualAddress;
DWORD SizeOfBlock;
// WORD TypeOffset[1];
} IMAGE_BASE_RELOCATION;
typedef IMAGE_BASE_RELOCATION UNALIGNED * PIMAGE_BASE_RELOCATION;Windows API #
After the PE file is loaded into memory and goes through the processes described above, how does this interact with Windows and its subsystems? This is where the Windows API (WinAPI) comes into play. The WinAPI is used to call certain functions that are exposed in Windows to interact with memory, processes, subsystems, and others. There are two main levels within execution: user space and kernel space. The former is where most applications are run along with segmentation that restricts lower level operations due to security reasons. The latter is where Windows carries out those operations and executes the syscalls. Syscalls are very low level CPU/hardware instructions that tell the computer what to do and how to do it.
When an application wants to do something, it will call its dedicated WinAPI function. Effectively the WinAPI function call is a wrapper for the NTAPI version of that call which is held in ntdll.dll. This is because the NTAPI is the gateway to the kernel space and by extension, its syscall which requires careful handling to make sure it is being called correctly. According to Microsoft, most of the NTAPI function calls are undocumented and if used, can be extremely unstable due to potential changes when there is an update. So the WinAPI is an effective way to keep the function calls stable with little change when there are updates to Windows. In other words, the application will call a WinAPI function. That function will call its NTAPI version which will transition it into kernel space and call its syscall.
0x0055 which is the corresponding syscall for the function during the writing of this post. However, syscall numbers can change (and frequently do).
Here Notepad.exe is trying to create a file. To do so it will use the CreateFileA WinAPI function. That function will call its NTAPI version which is NtCreateFile. Afterwards it will transition into kernel space and execute its syscall number in this case being 0x0055.
You can manually check the syscall numbers via debugging the syscall instruction during the execution of functions; OR look them up from historical databases like the one found here or here. For proof of concept, below is what the same syscall looks like in x64 assembly under the debugger:

Notice the mov instruction above the syscall. Specifically the bytes 55 is the syscall number for NtCreateFile. Some databases refer to the syscall number in decimal form; others refer to them in byte form similar to how it’s executed in assembly as seen above. Either way, 55 in bytes translates to 85 in decimal so keep an eye out for how they are represented.
-
Massive thanks to Ange Albertini for creating the PE diagrams found on his github! ↩︎
-
Very helpful diagram via infosecinstitute from Dejan Lukan ↩︎